
MapReduce[翻译]
MapReduce是一个编程模型,是一个与处理和生成大数据集相关的实现。用户指定一个处理键值对的 Map 函数生成一个中间键值对的集合,指定一个 Reduce 函数来合并有相同中间键的所有中间值。许多现实中的任务都可以用这种模型表达,像这篇论文中所展示的一样。
用这种函数风格写成的程序可以自动在大型商用机器集群上并行化执行。这个运行时系统负责分割输入数据的细节,调度程序在机器集群上执行,处理机器的错误和管理请求的内部机器通信。这样允许没有任何并行化和分布式系统经验的程序员可以轻松地利用大型分布式系统的资源。
我们实现的MapReduce运行在大型商业机器集群上并且是高度可拓展的:一个典型的MapReduce计算在数以千计的机器上处理许多兆兆字节(2^40字节)的数据。程序员发现这个系统使用起来是简单的:数以百计的MapReduce程序已经被实现,每天高达一千多个MapReduce工作正在Google的集群上执行。
目录
1 简介
在过去的五年里,作者和许多在Google工作的其他人实现了数百种有专用目的的计算,用来处理大量原始数据,例如爬取的文档,网络请求日志等等,计算多种多样的派生数据,例如反向索引,网页文档图结构的各种表示方式,爬取主机的页数摘要,在给定一天的最频繁查询集合等等。大多数此类计算在概念上是简单明了的。但是输入数据通常是巨大的,为了在合理的时间内完成计算必须分布在成百上千个机器上。怎样并行化计算,分布数据和处理错误这些问题共同困扰了原先使用大量复杂代码处理这些问题的简单计算。
为了应对这种复杂性,我们设计了一个新的抽象概念允许我们表达试图执行的简单计算,但是我们在库中隐藏了并行化,容错,数据分布和负载平衡的复杂细节。我们的抽象概念的灵感来源于当前在 Lisp 和许多其他函数式语言中的 Map 和 Reduce 原函数。我们意识到大多数我们的计算涉及到对输入数据的每一个逻辑“记录”应用一个 Map 操作来计算一组中间键值对,然后对共享同一个键的所有值应用一个 Reduce 操作适当地合并派生的数据。我们使用具有用户指定的 Map 和 Reduce 操作的函数模型,使我们方便地并行化进行大型计算,我们使用重新计算作为容错的主要机制。
这项工作的主要贡献是一个简单而又强大的接口,该接口能够自动实现大规模计算的并行化和分布,并且该接口的是实现在大型商业计算机集群上达到高性能。
第2节描述了基本的编程模型并且给出了若干实例。第3节 描述了为我们基于集群计算环境定制的MapReduce接口的实现。第4节描述了我们发现有用的对编程模型的一些改进。第5节对大量任务的实现进行了性能度量。第6节探索了MapReduce在Google的应用,包括我们将其作为重写产品索引系统的基础的经历。第7节讨论了与其相关的和未来的工作。
2 编程模型
计算会获取一个输入键值对集合,然后产生一个输出键值对集合。MapReduce库的用户通过两个函数:Map 和 Reduce 来表达计算。
由用户编写的 Map 函数获取一个输入对,产生一个中间键值对集合。MapReduce库将具有相同中间键 I 的中间值分成一组,然后把它们传递给 Reduce 函数。
Reduce 函数同样由用户编写,接受一个中间键 I 和一个与该键对应的中间值集合。它将这些值合并起来形成一个可能更小的值的集合。通常每一次 Reduce 调用仅仅产生零或一个输出值。中间值通过一个迭代器被提供给用户的reduce函数。这样允许我们处理太大而不能放入内存的值列表。
2.1 实例
考虑统计大量文档中每个单词出现次数的问题。用户需要编写类似于下面伪码的代码:
1 | map(String key, String value): |
map 函数发出(emit)每个单词加上一个相关的出现次数(在这个简单的例子中仅仅是“1”)。reduce 函数将每一个特定单词的所有发出的(emited)次数加在一起。
另外,用户需要编写代码用输入,输出文件的文件名和额外的调整参数填充 mapreduce 规范对象。用户然后调用 MapRedece 函数,将这个规范的对象传递给它。用户代码会被MapReduce库(用C++实现的)链接到一起。附录A包含了这个例子的所有程序文本。
2.2 类型
尽管之前的伪码是根据字符串输入输出编写的,但是概念上用户提供的map和reduce函数具有相关的类型:
1 | map (k1, v1) -> list(k2, v2) |
也就是说,输入键和值从不同于输出键和值的域中提取。另外,中间键和值与输出键和值来自同一个域。
我们的C++实现向用户定义的函数传递字符串,而从字符串转换为合适的类型留给用户定义的代码实现。
2.3 更多实例
这里有一些有趣而又简单的例子,这些例子能够轻易的表达成MapReduce计算。
Distributed Grep: 如果与提供的模式匹配,map函数会发出(emit)一行文本。reduce函数是一个identity函数,它仅仅将提供的中间数据复制到输出。
译者注:grep是Linux的一个命令,该命令会根据给定的模式查找文本中匹配的部分,如果匹配会输出所在行。
Count of URL Access Frequency: map函数处理网页请求日志,输出 <URL, 1> 。reduce函数将来自相同URL的值加在一起并且发出(emit)一个 <URL, total count> 键值对。
Reverse Web-Link Graph: map函数为在名为 source 的网页中找到的所以指向 target URL的每一个链接输出 <target, source> 键值对。reduce函数将与给定的目标URL有关的所有源URL列表连接起来,发出(emit)键值对: <target, list(source)>
Term-Vector per Host: 术语向量(term vector)将出现在一个文档或者一组文档中最重要的单词概括为 <words, frequence> 键值对。map函数为每一个输入文档发出(emit)一个 <hostname, term vector> 键值对(主机名从文档的URL中提取)。将给定主机所有文档的术语向量传递给reduce函数。它把这些术语向量加在一起,去掉不常出现的属于,然后发出(emit)一个最终的 <hostnamem, term vetor> 键值对。
Inverted Index: map函数解析每一个文档,然后发出(emit)*<word, document ID>* 键值对序列。reduce函数接收给定单词的所有键值对,根据文档ID排序,之后发出(emit)一个 <word, list(document ID)> 键值对。所有输出键值对构成的集合形成了一个简单的反向索引。这样很容易拓展计算来跟踪每个单词的位置。
Distributed Sort: map函数从每个记录中提取键,然后发出(emit)一个 <key, record> 键值对。reduce函数发出(emit)没有变化的全部键值对。这个计算依赖于在4.1节描述的隔离设施和在4.2节描述的可排序属性。
3 实现
MapReduce接口可能有多种不同的实现方式。正确的选择依赖于环境。例如,一种实现可能适合小型共享内存机器,另一种适合大型的NUMA多处理器,另一种适合更大的网络计算机集群。本节描述了一个针对Google广泛使用的计算环境:通过交换以太网连接在一起的大型商用计算机集群的实现。在我们的环境中:
- 机器通常是运行Linux系统的双X86处理器,每台有2-4G内存。
- 使用的是商用网络硬件,在机器级别上通常是100M/s或者是1G/s,但是平均考虑下来要少于一半的带宽。
- 一个集群包含成百上千台机器,因此机器故障是很常见的。
- 存储使用的是廉价的IDE磁盘,这些磁盘与单独的机器直接相连。使用内部开发的分布式文件系统管理存储在这些磁盘上的数据。文件系统使用拷贝的方式在不可靠的硬件之上提供实用性和可靠性。
- 用户提交作业到一个调度系统。每个作业由一系列任务组成,作业被调度器映射到集群内一系列可使用的机器上。
3.1 执行概述
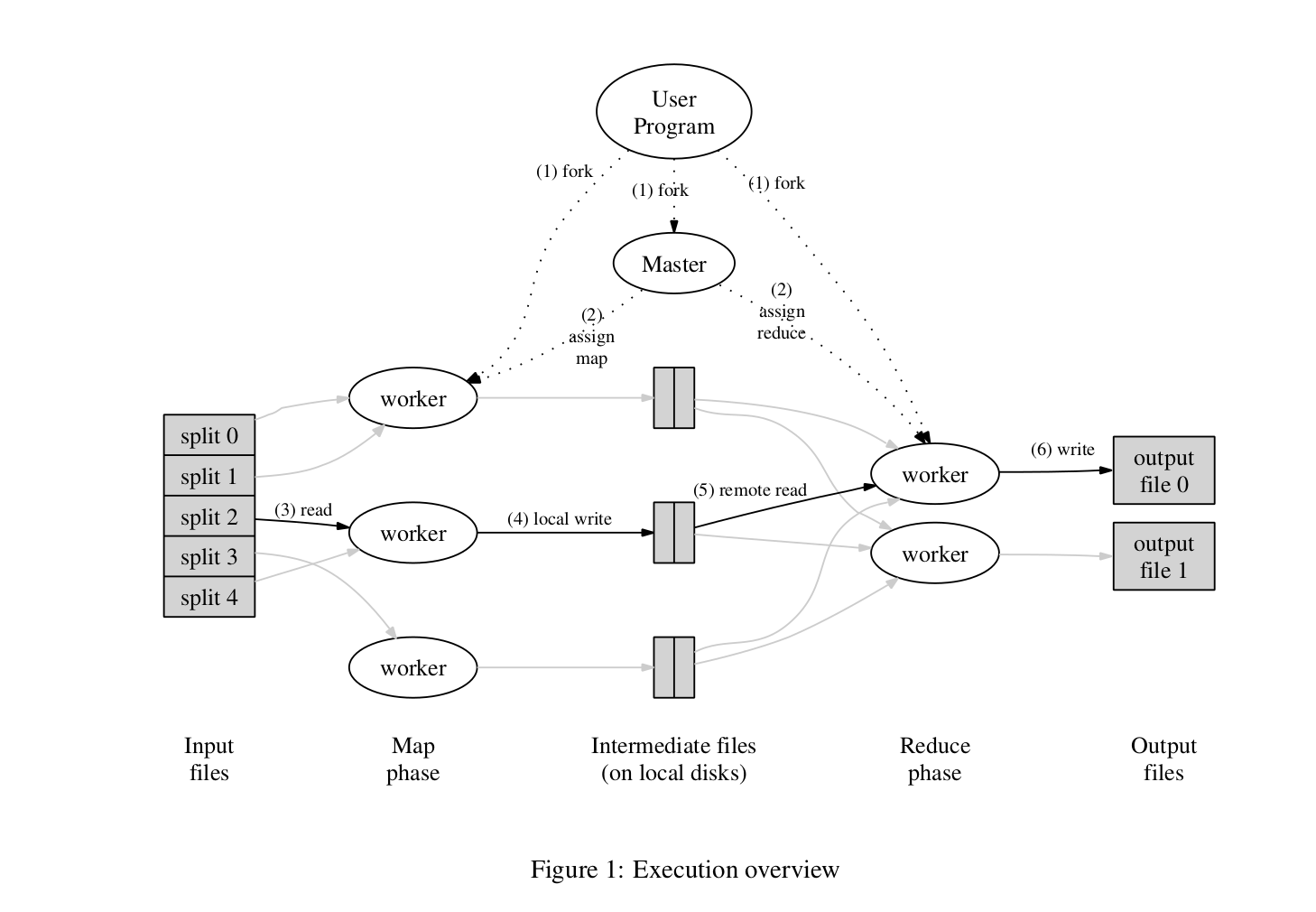
通过自动地将输入数据分割成 M 份,Map 函数的调用被分布在多台机器上。分割后的输入数据可以被不同的机器并行处理。使用分割函数(例如: hash(key) mod R)将中间键分成 R 份, Reduce 函数的调用也被分布化。分割的份数( R )和分割函数由用户指定。
图1展示了我们实现的MapReduce操作的全部流程。当用户程序调用MapReduce函数时,会发生以下一系列动作(图1中的数字标签对应下面列表中的编号):
- 用户程序中的MapReduce库首先将输入文件分成M份,通常每份是16MB或者64MB(用户可以通过一个可选参数控制)。然后在机器集群上启动多个程序副本。
- 这些程序副本当中有一个是特殊的——master。其余的是被master分配任务的worker。这里分配了 M 个map任务和 R 个reduce任务。管理程序找出空闲的worker然后给它分配一个map任务或者reduce任务。
- 被分配了map任务的worker从相应的输入文件中读取内容。它从输入数据中解析出键值对,将每一个键值对传递给用户定义的 Map 函数。Map 函数生成中间键值对并缓冲在内存中。
- 缓冲的键值对被周期性地写入本地磁盘,然后被分割程序分割成 R 份。这些在本地磁盘上缓冲的键值对的位置被传回master,master负责将这些位置向前传递给reduce worker。
- 当reduce worker被master告知中间键值对的位置时,它使用远程调用读取在map worker的磁盘上缓冲的数据。当reduce worker读取了全部的中间数据后,它通过中间键对读取数据排序,因此所有有相同键的数据被分成了一组。排序是必须的,因为通常会有许多不同的键映射到同一个reduce任务。如果中间数据的数量太大而不能装入内存,此时使用外部排序。
- reduce worker遍历已排序的中间数据,对于遇到的每个唯一的中间键,它将键和相应的中间值集合传递给用户的reduce函数。Reduce 函数的输出被附加到这个reduce分区的输出文件中。
- 当所有的map任务和reduce任务完成时,master唤醒用户程序。这时候,用户程序从MapReduce调用返回到用户代码中。
在顺利完成后,mapreduce执行结果保存在 R 个输出文件中(每一个reduce任务有一个输出文件,文件名由用户指定)。通常,用户不需要将这R 个输出文件合并成一个文件——他们通常将这些文件作为另一个MapReduce调用的输入,或者在另一个分布式应用中使用它们,这个分布式应用能够处理被分成多个文件的输入。
3.2 Master 数据结构
master保存多个数据结构。对于每一个map任务和reduce任务,它存储它们的状态(空闲,正在处理,已经完成)和worker机器的身份(对于非空闲任务)。(译者注:所谓的身份指的是该计算机运行的是map任务还是reduce任务)
master是一个将中间文件区的位置从map任务传输到reduce任务的管道。因此,对于每一个已经完成的map任务,master存储了由该map任务处理的 R 个中间文件区的位置和大小。当map任务完成时,接收位置和大小信息的更新。这些信息以增量的方式推送到正在处理reduce任务的worker。
3.3 容错性
因为MapReduce库的设计目的是帮助使用成百上千的机器处理大量数据,因此MapReduce库必须优雅地容忍机器故障。
Worker 故障
master会定期的ping(译者注:向计算机发送信号等待回复测试是否连通互联网)每一个worker。如果在一定时间内没有收到worker的响应,master会将该worker标记为故障。任何由worker完成的map任务都会被重置为初始的空闲状态,然后可以被其他worker调度。同样地,任何在故障的worker上处理的map和reduce任务也会被重置为空闲状态,变得可以被调度。
发生故障时已经完成的map任务会重新执行,因为它们的输出存储在故障机器的本地磁盘上,所以不能访问。已经完成的reduce任务不必重新执行,因为它们的输出存储在全局文件系统。
当map任务被一个worker A首次执行,之后又被worker B执行(因为A失败了)时,所有正在执行reduce任务的worker被通知重新执行。任何还没有从worker A读取数据的reduce任务将会从worker B读取数据。
MapReduce对于大规模worker故障具有弹性。例如,在MapReduce操作过程中,正在运行的集群的网络维护导致了80台机器在数分钟之内无法访问。MapReduce master简单地重新执行被这些不可访问的机器完成的工作,继续向前处理,最终完成MapReduce操作。
Master 故障
很容易使master写入上面描述的master数据结构的周期性检查点。如果master任务失败了,可以从上一次检查点状态启动一个新的备份。然而,鉴于只有一个master,它不太可能出现故障。因此,如果master故障了,我们当前的实现会终止MapReduce计算。用户可以检查状态,如果愿意可以重新尝试MapReduce操作。
表示故障的语义
当用户提供的map和reduce操作对于他们输入的值是确定性的函数,我们的分布式实现会产生和整个程序无错串行执行相同的结果。
我们依赖于map、reduce任务输出的原子性提交来实现这一特性。每一个正在处理的任务将它的输出写到私有临时文件。reduce任务会产生一个这样的文件,map任务会产生
当一个reduce任务完成时,reducer worker自动将它的临时输出文件重命名为最终输出文件名。如果同一个reduce任务在多个机器上被执行,那么将对同一个最终输出文件执行多次重命名操作。我们依赖于由底层文件系统提供的原子性重命名操作,来保证最终文件系统状态仅包含reduce任务的一个执行结果产生的数据。
我们绝大多数的map和reduce操作是确定性的,在这种情况下我们的语义与顺序执行是等价的,这使得程序员推理程序的行为非常容易。当map和reduce操作是非确定的,我们提供弱化但仍然可推理的语义。在非确定操作中会出现,一个特定reduce任务
考虑map任务
3.4 局部性
在我们的计算环境中,网络带宽是一个相对紧缺的资源。我们通过利用输入数据保存在组成集群的机器的本地磁盘上的优势来节约网络带宽。
3.5 任务粒度
3.6 备份任务
4 改进
4.1 分割函数
4.2 有序保证
4.3 合并函数
4.4 输入输出类型
4.5 副作用
4.6 跳过糟糕的记录
4.7 局部执行
4.8 状态信息
4.9 计数器
5 性能
5.1 集群配置
5.2 Grep
5.3 排序
5.4 备份任务的作用
5.5 机器故障
6 实验
6.1 大规模索引
7 相关工作
8 结论
致谢
致谢请查阅原论文,此处不做翻译。
参考文献
参考文献请查阅原论文。
A 单词频率
本节包含了一个程序,该程序统计了通过命令行指定的文件集合中的每一个单词的出现次数。
1 |
|
