
扩散模型
在ChatGPT成为万众瞩目的焦点之际,另一个AI应用也掀起了一小股热潮,那就是MidJourney。MidJourney是一个AI绘画应用,用户通过输入文字描述即可获得相应的图像。最新发布的Midjouney v5 进一步提高了图像生成质量,还解决了一直被诟病的手部细节问题,使人不得不感叹于人工智能的进步速度。除了MidJourney,DALL-E 2和Stable Diffusion也是为人所熟知的图像生成模型。而这三者背后采用的技术则都是以扩散模型(Diffusion Models)为基础的。
自2020年 DDPM(Denoising diffusion probabilistic models [1]) 发表以来,大量关于Diffusion Models 的论文如雨后春笋般层出不穷。仅CVPR 2023 就有100多篇的相关工作,其在学术界的热度可见一斑。Diffusion Models的原理看似简单,但其涉及的数学推导也着实令人头大。这篇文章将基于DDPM详细介绍扩散模型的原理,并给出笔者的一些理解。实际上,这篇文章是一份笔记,它主要参考了“Understanding Diffusion Models: A Unified Perspective”这篇论文。
目录
- What are Diffusion Models?
- Hierarchical Variational Autoencoders
- Variational Diffusion Models
- Reference
What are Diffusion Models?
首先,简单介绍一个常见的图像生成任务。给模型一组观测到的图像数据
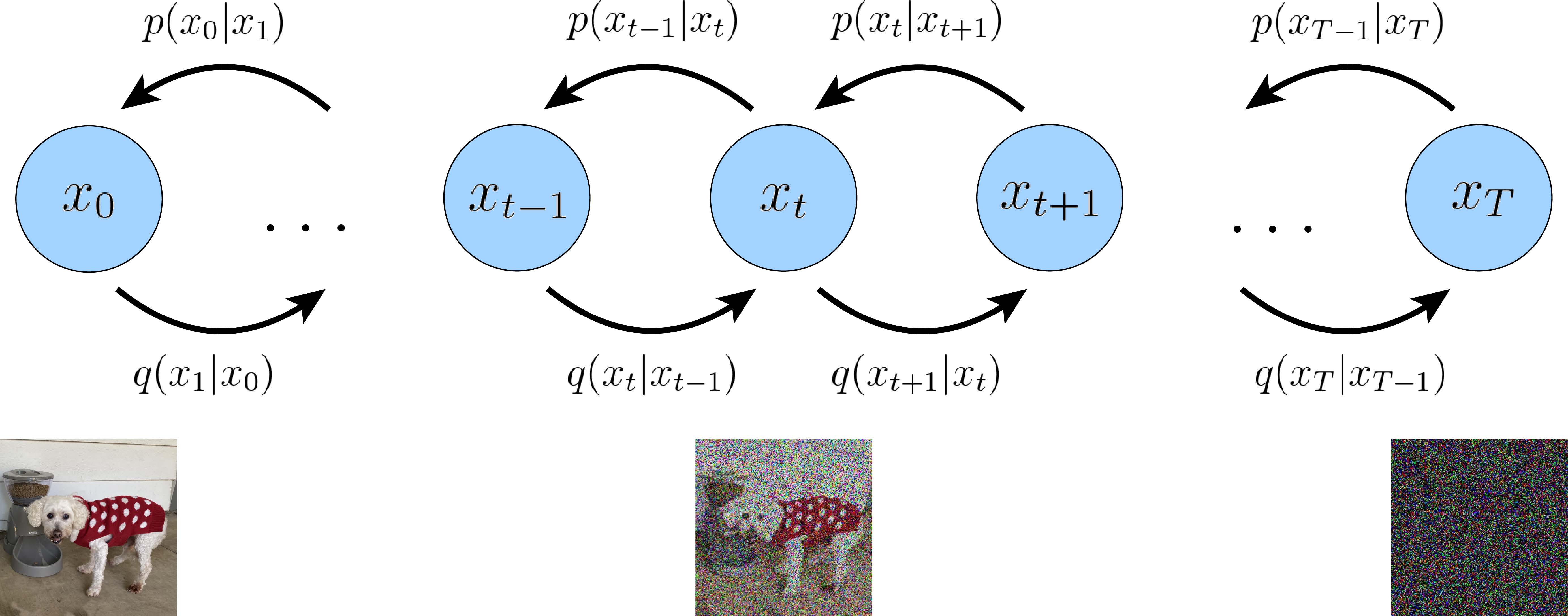
The illustration of diffusion models
简单来说,扩散模型包含两个过程:前向扩散过程和反向去噪过程。前向扩散过程是对一张图像逐渐添加高斯噪声直至变成随机噪声,而反向生成过程是去噪过程,我们将从一个随机噪声开始逐渐去噪直至生成一张合理的图像。
Diffusion Process
前向扩散过程对一张图像逐渐添加高斯噪声直至变成随机噪声,它可以看作一个固定的马尔可夫链(Markov chain)。给定原始数据
其中参数
其中,
公式(2)的证明如下:
推导过程利用了两个独立高斯随机变量之和仍然是高斯分布的事实。新分布的均值是两个均值的总和,方差也是两个方差的总和。Sum of two independent Gaussian random variables

Denoising Process
扩散过程是将数据噪声化,那么反向过程就是一个去噪的过程。如果我们知道反向过程中每一步的真实分布
然而,真实分布
接下来的问题就是如何对
从中可以看出,反向去噪也是一个逐步高斯采样的过程,不过它并不是马尔可夫链。因为
因此,我们也可以用类似的形式建模
在反向生成过程中,
上面介绍了扩散模型的前向扩散过程和反向去噪过程。然而,我们对于为何要如此建模以及如何优化尚且不明。接下来,我们将从分层变分自编码器(Hierarchical Variational Autoencoders)的角度切入。
Hierarchical Variational Autoencoders
让我们回到最初的问题。给模型一组观测到的图像数据,我们希望模型能够建模数据的真实分布,从而可以生成一组和数据尽可能相近的图像。由于真实数据的维度较高,存在着一些隐含的因素和规律,这些因素往往难以直接观察和描述,导致了建模的困难。通常,我们可以认为观察到的数据是由一个相关的看不见的隐变量
形式上,我们将隐变量
或者,根据概率的链式法则:
不论何种形式,我们都无法直接计算
不过,我们可以通过优化一个代理目标函数来最大化似然函数,即证据下界(Evidence Lower Bound, dubbed ELBO)。
Evidence Lower Bound (ELBO)
形式上,ELBO可以表达为:
其中,
由于KL散度总是大于等于0的,所以ELBO是
我们引入隐变量
因此,我们通过最大化ELBO实现了曲线救国。这一定程度上是无奈之举,因为直接优化KL散度行不通(真实后验分布
Variational Autoencoders
变分自编码器(Variational Autoencoders)就是通过直接最大化ELBO做生成任务的。其优化目标可以表示为:
在这种情况下,我们同时学习了一个编码器(Encoder)和一个解码器(Decoder)。编码器将输入数据
公式(13)包含了两项。第一项是重构项,它度量了解码器从变分分布中重建输入的重构损失,这确保了所学习的分布对隐变量进行了有效的建模,我们可以从中重新生成出原始数据。第二项则衡量了学习到的变分分布与隐变量的先验分布(一般是标准正态分布)之间的相似程度。
VAE通常将编码器建模为具有对角协方差的多变量高斯分布,并选择标准多变量高斯分布作为先验分布:
然后,ELBO中的KL散度可以解析计算,并且可以使用蒙特卡罗估计来近似重建项:
其中,
Hierarchical VAE
层次变分自动编码器(HVAE)是对VAE的推广,它将VAE扩展到了多层的隐变量。换句话说,隐变量本身被解释为由其他更高层次、更抽象的隐变量产生。
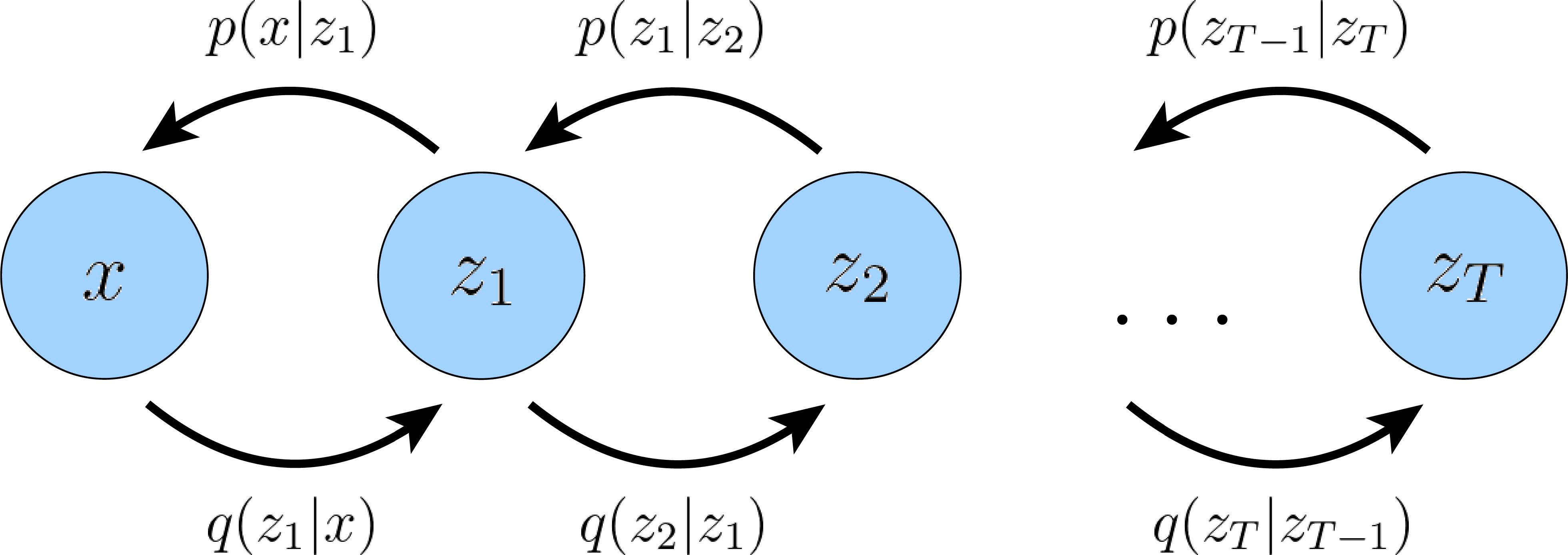
Hierarchical Variational Autoencoders
在
Variational Diffusion Models
有空再写,写不动啦,先鸽啦 (^_^)
Reference
[1]. Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in Neural Information Processing Systems, 2020, 33: 6840-6851.
[2]. Luo C. Understanding diffusion models: A unified perspective[J]. arXiv preprint arXiv:2208.11970, 2022.
